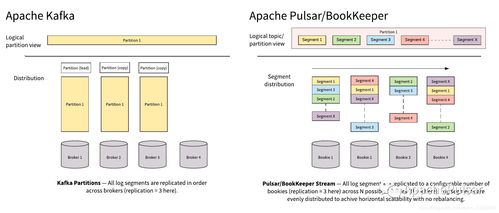
Pulsar vs. Kafka 以Segment為中心的架構(gòu)及其對數(shù)據(jù)處理與存儲支持服務(wù)的啟示
在當(dāng)今的大數(shù)據(jù)與實(shí)時計算領(lǐng)域,Apache Pulsar和Apache Kafka作為兩大核心消息流平臺,其設(shè)計哲學(xué)與架構(gòu)選擇深刻影響著企業(yè)的數(shù)據(jù)處理和存儲支持服務(wù)。特別是兩者在“以Segment為中心”的架構(gòu)理念上的異同,成為了理解其性能、可擴(kuò)展性和運(yùn)維復(fù)雜性的關(guān)鍵。本文旨在深入探討這一架構(gòu)特性,并分析其對構(gòu)建健壯數(shù)據(jù)處理與存儲服務(wù)體系的支撐作用。
核心架構(gòu)理念:Segment的引入
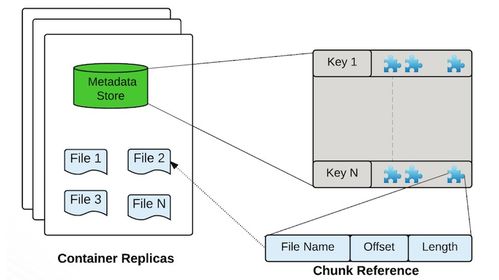
傳統(tǒng)消息隊列或早期流處理系統(tǒng)常將主題(Topic)視為一個連續(xù)的、不可分割的日志。而“以Segment為中心”的架構(gòu),其核心思想是將一個主題的持久化日志在物理上分割成多個更小、更易管理的部分——即Segment(在Kafka中稱為Log Segment,在Pulsar中稱為Ledger Segment)。這種設(shè)計帶來了根本性的變革:
- 存儲與計算的解耦:Segment作為獨(dú)立的存儲單元,使得存儲層可以從服務(wù)層(Broker)中抽象出來。Pulsar將這一理念貫徹得更為徹底,其分層架構(gòu)明確分離了無狀態(tài)的服務(wù)層(Brokers處理消息傳遞)和持久的存儲層(BookKeeper集群以Segment形式存儲數(shù)據(jù))。Kafka雖然依賴其Broker節(jié)點(diǎn)本地磁盤存儲Segment,但其底層同樣基于Segment文件進(jìn)行日志管理。
- 無限的橫向擴(kuò)展與獨(dú)立伸縮:由于Topic被劃分為多個Segment,新數(shù)據(jù)可以寫入新的Segment,而舊的Segment可以被獨(dú)立地歸檔、遷移或刪除。這為存儲容量的無限水平擴(kuò)展和獨(dú)立于計算資源的存儲伸縮提供了可能。Pulsar借助BookKeeper,可以輕松地將舊的Segment從高性能存儲(如SSD)卸載到低成本對象存儲(如S3),實(shí)現(xiàn)分層存儲。
- 并發(fā)的讀寫與高效的數(shù)據(jù)管理:多個Segment可以支持更高程度的并行讀寫操作。例如,在數(shù)據(jù)回溯(Backfill)或追趕消費(fèi)(Catch-up Consumption)時,可以并行讀取多個歷史Segment,極大提升了吞吐量。Segment作為獨(dú)立的清理、壓縮和保留策略單元,使得數(shù)據(jù)生命周期管理更加精細(xì)和高效。
Pulsar與Kafka的實(shí)現(xiàn)對比
盡管共享“Segment”這一核心概念,但Pulsar和Kafka在具體實(shí)現(xiàn)和由此帶來的服務(wù)支持能力上存在顯著差異:
- Pulsar的Segment(Ledger)與分層架構(gòu):
- 存儲完全解耦:Pulsar的Segment(在BookKeeper中稱為Ledger)完全存儲在獨(dú)立的BookKeeper存儲集群中。Broker節(jié)點(diǎn)不持有數(shù)據(jù),僅提供消息路由和服務(wù)發(fā)現(xiàn)。這種徹底的分離帶來了極高的彈性——Broker可以快速故障恢復(fù)或無狀態(tài)擴(kuò)展,存儲層可以獨(dú)立進(jìn)行擴(kuò)縮容和優(yōu)化。
- Segment即服務(wù)邊界:每個Segment(Ledger)在BookKeeper中被復(fù)制到多個存儲節(jié)點(diǎn)(Bookie)上,其生命周期(創(chuàng)建、密封、刪除)由Broker精細(xì)控制。這為Pulsar原生支持多租戶、命名空間級別的存儲隔離和配額管理奠定了堅實(shí)基礎(chǔ)。
- 對存儲支持服務(wù)的直接影響:這種架構(gòu)使得Pulsar能夠原生、無縫地集成分層存儲(Tiered Storage)。冷數(shù)據(jù)的Segment可以被透明地卸載到對象存儲,而對客戶端完全無感知。這極大地降低了長期數(shù)據(jù)保留的成本,是構(gòu)建大規(guī)模歷史數(shù)據(jù)平臺的理想選擇。
- Kafka的Log Segment與本地存儲:
- 存儲與計算耦合:Kafka的Segment是存儲在Broker本地磁盤上的物理文件序列。每個Broker負(fù)責(zé)其分配到的分區(qū)(Partition)的所有Segment的讀寫和存儲。這種設(shè)計簡單高效,延遲極低,因?yàn)閿?shù)據(jù)訪問是本地化的。
- Segment作為本地文件管理單元:Kafka依賴操作系統(tǒng)的頁緩存和高效的順序I/O來保證性能。Segment的滾動、索引和清理策略是Kafka高性能的關(guān)鍵。存儲的擴(kuò)展與Broker節(jié)點(diǎn)綁定,擴(kuò)容數(shù)據(jù)分區(qū)通常需要重新分配數(shù)據(jù),過程相對復(fù)雜。
- 對存儲支持服務(wù)的直接影響:Kafka本身不原生支持與遠(yuǎn)程/對象存儲的透明分層。雖然可以通過如Kafka Connect等工具將數(shù)據(jù)歸檔到S3,或使用Confluent的特定功能,但這并非核心架構(gòu)的一部分,可能增加運(yùn)維復(fù)雜性。其存儲支持更側(cè)重于通過增加Broker節(jié)點(diǎn)和調(diào)整本地存儲配置來進(jìn)行橫向擴(kuò)展。
對數(shù)據(jù)處理與存儲支持服務(wù)的意義
以Segment為中心的架構(gòu),特別是Pulsar所代表的完全解耦模式,為現(xiàn)代數(shù)據(jù)處理和存儲支持服務(wù)帶來了深遠(yuǎn)影響:
- 服務(wù)可用性與運(yùn)維簡化:存儲與計算的分離允許兩者獨(dú)立故障恢復(fù)、升級和擴(kuò)縮容。在Pulsar中,替換一個Broker幾乎瞬時完成,不影響數(shù)據(jù)持久性;存儲層(Bookie)可以獨(dú)立進(jìn)行硬件升級。這大幅提升了整個服務(wù)的可用性和運(yùn)維靈活性。
- 成本優(yōu)化與彈性存儲:通過分層存儲,熱數(shù)據(jù)保存在高性能介質(zhì)以滿足低延遲需求,而海量冷數(shù)據(jù)可自動遷移至低成本對象存儲。這實(shí)現(xiàn)了存儲成本的階梯式優(yōu)化,特別適合需要長期合規(guī)性存儲或進(jìn)行大規(guī)模歷史數(shù)據(jù)分析的場景。
- 云原生與多租戶支持:Segment作為獨(dú)立的資源單元,便于在云環(huán)境中進(jìn)行計量、配額和隔離。Pulsar的架構(gòu)天生適合云原生部署和強(qiáng)大的多租戶支持,能為不同團(tuán)隊或應(yīng)用提供隔離的、帶有服務(wù)質(zhì)量保證(QoS)的消息和存儲服務(wù)。
- 統(tǒng)一的數(shù)據(jù)服務(wù)層:這種架構(gòu)促進(jìn)了流存儲(Stream Storage)概念的形成,即消息系統(tǒng)不再僅僅是管道,而是一個可重放、可長期保留的可靠存儲系統(tǒng)。Pulsar的“流原生”設(shè)計使其能夠統(tǒng)一實(shí)時處理和批處理的數(shù)據(jù)源,簡化了Lambda或Kappa架構(gòu)的數(shù)據(jù)基礎(chǔ)設(shè)施。
結(jié)論
Apache Pulsar和Apache Kafka都通過“以Segment為中心”的架構(gòu)解決了大規(guī)模數(shù)據(jù)流的核心存儲問題。Kafka的方案更注重簡單性和極致的本地I/O性能,在計算與存儲緊密協(xié)同的場景下表現(xiàn)出色。而Pulsar通過將Segment抽象為完全獨(dú)立的存儲單元,并實(shí)現(xiàn)服務(wù)與存儲的徹底分離,構(gòu)建了一個在彈性、可擴(kuò)展性、多租戶和成本優(yōu)化方面更具優(yōu)勢的平臺,尤其適合于構(gòu)建企業(yè)級、云原生的統(tǒng)一數(shù)據(jù)處理和存儲支持服務(wù)。選擇何者,最終取決于企業(yè)在性能、運(yùn)維復(fù)雜度、長期成本以及未來架構(gòu)演進(jìn)路線上的具體權(quán)衡。
如若轉(zhuǎn)載,請注明出處:http://m.lzybdc.com/product/46.html
更新時間:2026-05-26 22:05:23