大數(shù)據(jù)Hadoop集群下的離線數(shù)據(jù)存儲與挖掘分析架構(gòu) 數(shù)據(jù)處理與存儲支持服務(wù)詳解
在大數(shù)據(jù)時代,面對海量數(shù)據(jù)的存儲與深度分析需求,基于Hadoop生態(tài)系統(tǒng)的離線數(shù)據(jù)處理架構(gòu)已成為企業(yè)級數(shù)據(jù)基礎(chǔ)設(shè)施的核心。本章將深入探討Hadoop集群環(huán)境下,離線數(shù)據(jù)的存儲體系、挖掘分析架構(gòu)以及關(guān)鍵的數(shù)據(jù)處理與存儲支持服務(wù)。
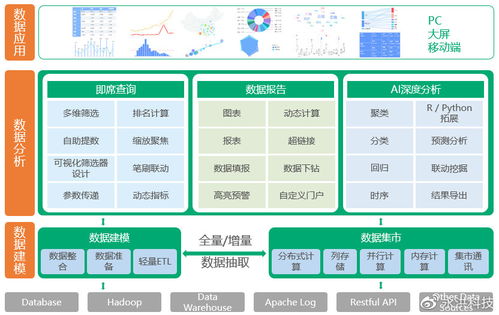
一、Hadoop集群離線數(shù)據(jù)存儲架構(gòu)
Hadoop分布式文件系統(tǒng)(HDFS)構(gòu)成了離線數(shù)據(jù)存儲的基石。其高容錯、高吞吐量的特性,使其能夠穩(wěn)定存儲PB級別的原始數(shù)據(jù)、清洗后的數(shù)據(jù)以及各類中間結(jié)果。通常,存儲架構(gòu)采用分層設(shè)計:
- 原始數(shù)據(jù)層:直接接入來自日志、數(shù)據(jù)庫、物聯(lián)網(wǎng)設(shè)備等的原始數(shù)據(jù),通常以原始格式(如文本、序列文件)存儲。
- 清洗整合層:對原始數(shù)據(jù)進行清洗、去重、格式標準化等預(yù)處理后存儲,為后續(xù)分析提供高質(zhì)量數(shù)據(jù)源。
- 輕度匯總層/數(shù)據(jù)倉庫層:根據(jù)業(yè)務(wù)主題,對數(shù)據(jù)進行輕度聚合或構(gòu)建維度模型,存儲在如Hive表中,支持靈活的交互式查詢。
- 數(shù)據(jù)集市/應(yīng)用數(shù)據(jù)層:為特定分析場景或應(yīng)用(如報表、機器學(xué)習(xí))高度聚合和優(yōu)化的數(shù)據(jù)。
二、離線數(shù)據(jù)挖掘與分析架構(gòu)
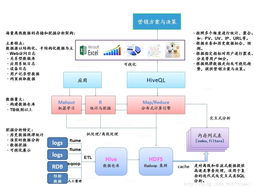
以MapReduce、Spark等計算框架為核心,構(gòu)建了強大的離線批處理分析能力。典型的分析架構(gòu)遵循“數(shù)據(jù)管道”模式:
- 數(shù)據(jù)采集與接入:使用Flume、Sqoop等工具將數(shù)據(jù)從各源頭穩(wěn)定導(dǎo)入HDFS。
- 數(shù)據(jù)計算與處理:這是核心環(huán)節(jié)。利用MapReduce進行海量數(shù)據(jù)的復(fù)雜ETL(提取、轉(zhuǎn)換、加載);或使用Spark及其MLlib庫,憑借內(nèi)存計算優(yōu)勢,進行迭代式計算和機器學(xué)習(xí)模型訓(xùn)練,效率更高。計算任務(wù)通常由YARN等資源調(diào)度器統(tǒng)一管理。
- 分析與挖掘應(yīng)用:基于處理后的數(shù)據(jù),業(yè)務(wù)分析師通過Hive、Spark SQL進行即席查詢;數(shù)據(jù)科學(xué)家使用Spark MLlib、Mahout等構(gòu)建和運行挖掘模型(如聚類、推薦、預(yù)測)。
- 結(jié)果輸出與服務(wù):分析結(jié)果可寫回HDFS,或?qū)С鲋陵P(guān)系型數(shù)據(jù)庫、NoSQL數(shù)據(jù)庫,供前端報表系統(tǒng)、推薦引擎等應(yīng)用調(diào)用。
三、關(guān)鍵的數(shù)據(jù)處理與存儲支持服務(wù)
為確保整個架構(gòu)高效、穩(wěn)定、易用,一系列支持服務(wù)不可或缺:
- 資源管理與調(diào)度服務(wù):YARN作為Hadoop 2.0后的核心組件,負責集群資源(CPU、內(nèi)存)的統(tǒng)一管理和調(diào)度,允許多個計算框架(如MapReduce, Spark)共享集群資源,提高利用率。
- 數(shù)據(jù)倉庫與SQL化服務(wù):Apache Hive將結(jié)構(gòu)化的數(shù)據(jù)文件映射為數(shù)據(jù)庫表,并提供HiveQL查詢語言,將復(fù)雜的MapReduce程序簡化為類SQL語句,極大降低了數(shù)據(jù)分析門檻。其元數(shù)據(jù)存儲在獨立數(shù)據(jù)庫(如MySQL)中。
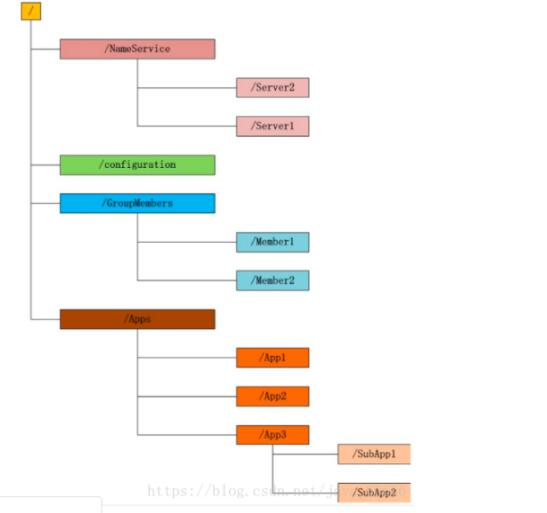
- 協(xié)調(diào)與元數(shù)據(jù)管理服務(wù):ZooKeeper提供分布式協(xié)調(diào)服務(wù),保障集群高可用,管理配置信息、命名服務(wù)等。對于更上層的數(shù)據(jù)治理,Apache Atlas等工具可提供數(shù)據(jù)血緣、分類和集中式元數(shù)據(jù)管理。
- 工作流調(diào)度與監(jiān)控服務(wù):Apache Oozie或Azkaban等工具用于編排和調(diào)度復(fù)雜的、依賴關(guān)系的Hadoop作業(yè)(如Hive、Spark、Sqoop任務(wù))形成工作流,實現(xiàn)自動化數(shù)據(jù)處理流水線。需配合集群監(jiān)控工具(如Ambari, Grafana+Prometheus)監(jiān)控集群健康狀態(tài)與作業(yè)性能。
- 數(shù)據(jù)格式與壓縮服務(wù):合理使用列式存儲格式(如ORC, Parquet)與壓縮算法(如Snappy, LZO),能極大提升存儲效率和查詢性能,是優(yōu)化存儲成本的關(guān)鍵。
一個成熟的大數(shù)據(jù)Hadoop離線處理架構(gòu),是存儲、計算、調(diào)度、管理服務(wù)的有機整合。它通過HDFS實現(xiàn)海量數(shù)據(jù)的可靠存儲,依托YARN、Spark等框架完成高效計算與深度挖掘,并借助Hive、Oozie、ZooKeeper等一系列支持服務(wù),將強大的底層能力封裝為穩(wěn)定、易用的數(shù)據(jù)生產(chǎn)力平臺,從而為企業(yè)決策、用戶洞察和智能應(yīng)用提供堅實的數(shù)據(jù)支撐。隨著云原生和存算分離趨勢的發(fā)展,此架構(gòu)仍在持續(xù)演進,但其核心思想與服務(wù)體系依舊具有重要指導(dǎo)價值。
如若轉(zhuǎn)載,請注明出處:http://m.lzybdc.com/product/45.html
更新時間:2026-05-26 03:07:35